Platform Engineers hate these 5 simple patterns for packaging AWS Lambda functions

There are many ways to manage cloud infrastructure and code we cram on it. In working with projects from the scale of one person’s hobby project to a service supporting millions of daily users there are considerations on how to deploy and deliver stuff in the cloud. When looking particularly at cloudy Serverless deployments here are some 5-ish patterns I like for handling the delivery, why, and the considerations involved.
I think it’s important to emphasise that the needs of a small project with a couple of functions and a single developer will vary significantly from a project with large development teams, several workflows and product ownership focuses. I wouldn’t want the entire application to be deployed every time a team added a new widget; these should be atomic changes with the smallest possible blast radius and our delivery mechanisms should serve that need.
Everything I’m about to whine on about has working code examples here: https://github.com/avaines/terraform_lambda_build_options and I’ve tried to ensure these are in the simplest form I could to get the pattern across.
I’ve set out some basic requirements which I would want to achieve with a workflow of anything at scale. These are:
- Lambda function code should be versioned, promotable, and targetable. An environment should be able to use a specific code version.
- The code a function is running should be identifiable and retrievable for analysis.
- Functions should not be replaced unless a change has occurred.
1) The Classic: copy-&-paste from the docs
Sample Code: https://github.com/avaines/terraform_lambda_build_options/tree/main/option1
First up is the easiest option; it’s what the Terraform documentation shows, so just copy, paste and switch up the file names and we are good to go!
Terraform’s documentation for the aws_lambda_function resource https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/lambda_function
It looks something like this:
data "archive_file" "lambda" {
...
}
resource "aws_lambda_function" "test_lambda" {
filename = data.archive_file.lambda.output_path
source_code_hash = data.archive_file.lambda.output_base64sha256
...
}
A very simple chain of resources, Terraform’s archive provider ZIPs up the Lambda code, creates a aws_lambda_function resource and provides the code bundle.

The Terraform dependency graph is really simple to follow. We’ve got some code, a Lambda function and an IAM role all attached.

How does that stack up against the requirements I set out at the start?
Lambda function code should be versioned, promotable, and targetable. An environment should be able to use a specific code version. Assuming the Lambda code is always in a Git repo and changes are checked in as part of the workflow.
We don’t produce any artefacts that other deployments can reuse as the code is bundled at apply-time, we can’t promote a Lambda to another stage like Dev to UAT or into production without re-bundling it. If we can’t do that we can expect “Well, it worked in my environment” to be whispered from the shadows at some point.
The code a function is running should be identifiable and retrievable for analysis. We’d need to add something like the commit ID as a resource tag and we would have to rely on the AWS Lambda ‘versioning’ to retrieve old versions as not every commit to the repo would be a change to the running code.
We could tag the Lambda with a commit ID- in theory the specific commit can be checked out. However, if you wanted to know what code was running on a previous version of the lambda, the tags wouldn’t help.
Functions should not be replaced unless a change has occurred. Big fail.
If the project is small and there isn’t any CI/CD to speak of and deployments are done from one’s laptop, two sequential runs of the terraform apply command wouldn’t cause the Lambda functions to be re-deployed. However, ZIP files have an annoying header which includes the last modification date & time, any ZIP file created, even from identical files, at the byte level will always end up with a different checksum value.
If we have multiple developers doing builds or have nice workflows with ephemeral build runners (like GitHub actions), each time the repo gets cloned the files have a new modification date on the file system (they didn’t exist before they got cloned).
Unfortunately, the Terraform archive_file resource only supports ZIP files, if we could handle Tarballs or something else that might solve the problem, I hear you say. It wouldn’t though as the AWS Lambda service will only take a ZIP file or a direct upload of files.
2) Did somebody say Shellscript?
Sample Code: https://github.com/avaines/terraform_lambda_build_options/tree/main/option2
If we start to think of the packaging of code and infrastructure changes as two separate phases of deploying the application we have some extra options.
By introducing a script or other tooling which is responsible for bundling code up into ZIP files and uploading that to S3, the Terraform code can ensure that the latest packaged code is deployed to the Lambda function. It also means that we have versioned build artefacts and through tags and metadata we can start to make our builds reuse code packages.
By adding a hash and a commit-id tag to the files we upload and the source_code_hash field on the aws_lambda_function resources, we can trigger builds when the code has changed. By implementing some logic into build pipelines to only package up functions when things have actually changed, Terraform is no longer going to try to re-deploy code unnecessarily.


How does that stack up against the requirements I set out at the start?
Lambda function code should be versioned, promotable, and targetable. An environment should be able to use a specific code version.
This now works a bit smoother, the code we build is being decoupled from the code that deploys it meaning that if we build the code and tag the bundles properly they are promotable, versioned artefacts we can reuse. Hurray!
The code a function is running should be identifiable and retrievable for analysis.
By running something like the example script found here: https://github.com/avaines/terraform_lambda_build_options/blob/main/src/helper_scripts/get-version-sha-sums.sh we can retrieve the SHA sums for all previous builds and the commits they came from.

These will all correspond nicely with what the AWS Lambda console will display about a given function version. We now have an auditable set of infrastructure. Well… this function anyway.
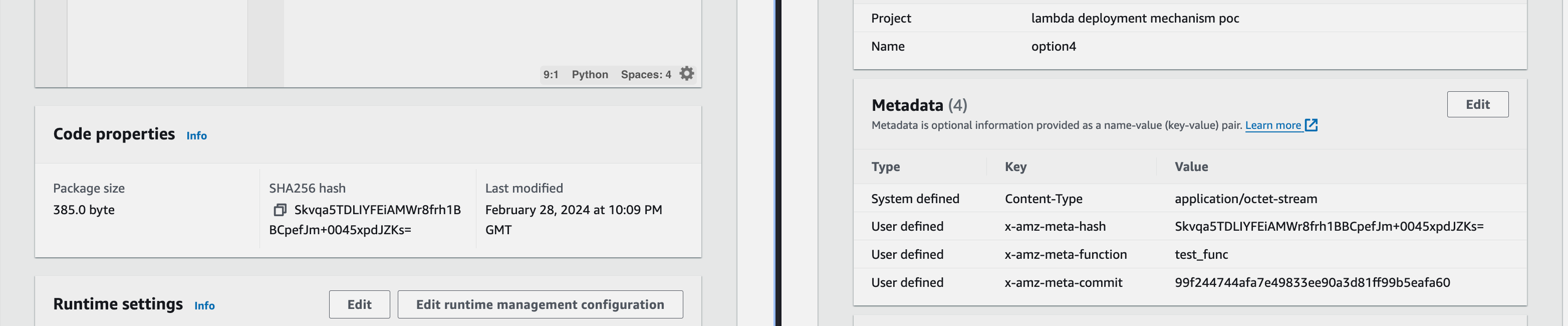
Functions should not be replaced unless a change has occurred.
Because the source_code_hash field is now the trigger for the resource to be re-deployed, no new code means no deployment.
3) The Lie
This one doesn’t really work, sorry. Seems like it should though doesn’t it?

I’ve included it even though it’s broken, as it seems like the obvious next step from Option 2. Having Terraform trigger the packaging script if the object doesn’t exist in S3 using a combination of data, null and external resources to achieve the goal. Terraform is ultimately a declarative tool and the statement “if the file exists in S3, reference it with a data resource; otherwise run this script to create it” is imperative and therefore bad Terraform-ju-ju.
There’s also an issue of running the script. Typically you’d use a null_resource to do this, however they only run at apply-time so any plan activities are going to fail if there isn’t already an item in S3. You can use an external resource to work around this slight limitation, though it does introduce other challenges for this option.
Finally referencing the S3 object once it exists in a way that lets us handle the source code hash, object key, and the object itself is just going to be a mess. More and more of this is going to have to go out into scripts. Once your Terraform repo is a glorified script-runner, you’re doing it wrong. Pick another tool.
 .
.
There’s an explanation of why this doesn’t work on the Hashicorp forums here: https://discuss.hashicorp.com/t/create-terraform-resource-s3-bucket-object-if-already-doesnt-exists/24247
4) 1+2=4(ish)
Sample Code: https://github.com/avaines/terraform_lambda_build_options/tree/main/option4
Sort of like option 1 where Terraform is responsible for the build and packaging of the code but with the benefits option 2 brought in.

A Terraform archive_file data resource is responsible for packaging. We check the current Git reference and upload the archive to S3 with metadata tags. With a bit of logic on the source_code_hash we can use the current Git commit ID to ensure any two builds from the same commit don’t result in new artefact deployments.

How does that stack up against the requirements I set out at the start?
Lambda function code should be versioned, promotable, and targetable. An environment should be able to use a specific code version.
All that is now possible without any of the downsides on either Option 1 or Option 2; the functionality allows us to stop rebuilding code and deploying it unnecessarily with minimal complexity and no additional tooling.
4.5) Bonus solution
Sample Code: https://github.com/avaines/terraform_lambda_build_options/tree/main/option4.5
Every serverless solution I’ve seen at a reasonable scale ends up with a ‘common’ or ‘shared’ library. Usually, this is where stuff like logging or business rule validation code lives and needs packaging up with your Lambdas. The archive_file data resource doesn’t support zipping up multiple directories.
Combining a bit of the thought in the broken-option3 solution and invoking a packaging script but without trying to check for some sort of conditional build logic, we can remain declarative but still have our cake and eat it. This packaging script is responsible for ‘staging’ a directory with our Lambda and our common libraries before the archive_file does its thing.

5) Decouple, Separate, & Empower
Sample Code: https://github.com/avaines/terraform_lambda_build_options/tree/main/option5
A particularly mature and large deployment may need to go down the route of option 2 and extend it out a bit further. By having Terraform just deploy a dummy code bundle to the Lambda in its initial state, a packaging and deployment workflow can be implemented.
One script packages up the code and another one does the identification logic to figure out which code version should be used and trigger the function deployment. This way of working allows for development teams and DevOps teams to work on much smaller units of concern and make the blast radius for any change as small as possible. It does however mean you now need 3 pipelines/workflows to deploy the application which is probably excessive for small projects or teams.


Super, now what?
That’s kinda up to you, just don’t do option 3- please.
Depending on the size of a project you should make appropriate decisions. You obviously can’t predict a project that will grow into a success but sometimes you can plan for areas which might be tech debt in future and mechanisms which let you engineer around it.
I ran some numbers, which prove that all the solutions are immaterial- it comes down to planning, requirements, and what you need to achieve.
| Option | Build time | State file size |
|---|---|---|
| Option 1 | 16s | 8K |
| Option 2 | 20s | 8K |
| Option 3 | N/A | N/A |
| Option 4 | 18s | 12K |
| Option 4.5 | 18s | 12K |
| Option 5 | 21s | 8K |